1. Numerical computations¶
This session will cover in some detail a number of topics that are very important in the implementation of computer programs for numerical mathematics. We are going to be mainly concerned with the floating-point representation of numbers and its implications in practice. The material included below is largely self-contained, although I shall assume that you are familiar with converting whole numbers from base 10 to base 2 (converting decimal fractions to binary is included below for your convenience).
The first part of this session provides an informal overview of floating-point numbers, without going into much mathematical detail; the remaining sections are more formal and are meant to provide a more in-depth coverage of this topic and its related aspects. The references at the end of this document contain additional material that you might want to consult to learn more about floating point numbers.
(the material included below is optional)
General overview¶
Real numbers are represented as floating-point numbers when they are stored in digital computers.
The floating-point format for representing real numbers is a variation on the usual scientific notation with which you are familiar (e.g., from school). For example, consider the base-10 number (written in scientific notation):
$7.03 \times 10^{11}$.
This number is represented by using: a mantissa (7.03), a base (10), and an exponent ($11$). The mantissa typically has some fixed number of places of accuracy; it can be represented in base 2, base 10, and so on. There is generally a limited range of exponents. Because of the highlighted requirements, the set of floating-point numbers will always be finite -- this leads us to one of its main limitations: the distance between two succesive values in this set is not uniform. By way of example, let's assume that we can only use 3 digits to store the mantissa, while the exponent can only range between $-10$ and $10$. For numbers close to zero, the "distance" between adjacent numbers from our set is very small. Indeed, if $x=1.72\times 10^{-10}$ and $y=1.73\times 10^{-10}$, then the distance between these two consecutive numbers is $0.000000000001$. On the other hand, if $x=6.33\times 10^{10}$ and $y=6.34\times 10^{10}$, then the distance between these two consecutive values is $100$ million. It should be clear that in our hypothetical floating-point number system calculations with large numbers will not be very accurate.
There are multiple equivalent representations of a number when expressed in scientific notation. For example:
$7.00\times 10^5$ or $0.70\times 10^6$ or $0.07\times 10^7$.
By convention, we shift the mantissa (a process usually referred to as adjusting the exponent) until there is exactly one non-zero digit to the left of the decimal point. When a number is expressed in this way it is said to be normalised. In our above list, only $7.0\times 10^5$ is normalized.
Typically, the mantissa is normalised when stored in the computer's memory, and then the mantissa and the exponent are both converted to base-2 and packed into a 32- or 64-bit word. If more bits were allocated to the exponent, the overall range of the format would be increased at the expense of decreasing the accuracy (as fewer bits would be available for storing the mantissa). The current system used by computers is a trade-off between memory space and accuracy (there are slight variations how this translates in practice, for each computer system).
During the 1980s the Institute for Electrical and Electronics Engineering (IEEE) produced a standard for the floating-point format. The title of the standard is "IEEE 754-1985 Standard for Binary Floating-Point Arithmetic" (see Wikipedia for more details). This is on most computers in use today (this standard has also been revised a number of times over the years). The upshot of this is that if you write a numerical computer program and test it at home on your personal laptop, you'll get very similar results when you try it on a different computer (e.g., in a Uni computer lab), provided that the computers have the same CPU architecture; more about this later.
ASIDE: converting decimal fractions to binary¶
This can be done very easily by using an iterative process:
- Start with the decimal fraction and multiply by 2.
- Stop if the result is 0 (terminated binary) or a result you've seen before (repeating binary).
- Record the whole number part of the result.
- Repeat from the first step with the fractional part of the result.
Examples: a). 0.75
0.50*2 = 1.0
0.0
b). 0.375
0.75*2 = 1.5
0.5*2 = 1.0
0.0
c). 0.1
0.2*2 = 0.4
0.4*2 = 0.8
0.8*2 = 1.6
0.6*2 = 1.2
0.2*2 = 0.4
$$ 0.0\overline{0011} $$
(although other notations are also possible).
Before we tackle the technicalities included below it helps to have an idea how information is stored inside a computer. Deep inside, it uses a binary system (like the one mentioned above). The smallest unit of information, called a bit, can have only two states: 'yes' or 'no', 'true' or 'false', $0$ or $1$; here, we stick to the $0$ and $1$ notation. A larger unit is called byte, which is a collection of $8$ bits. The byte can represent $2^8=256$ different states, which can encode numbers from $0$ to $255$ or $-128,\dots 0,\dots 127$ or a symbol of an alphabet. Modern computers use chunks of $8$ bytes, or $64$ bits to store information.
Floatig-point representation¶
A floating point number is a real number of the form
$$ \pm(0.d_1d_2\dots d_p)\times\beta^n\,, $$
where $d_1\neq{0}$, $0\leq d_i\leq \beta-1$, and $-e_{min}\leq n \leq e_{max}$.
Here, $p$, $n$, $e_{min}$ and $e_{max}$ are fixed values. The (finite) set of all such numbers is usually denoted by $F$.
NOMENCLATURE:
- $\beta$ is the base; the most common bases are $\beta=2$ (binary), $\beta=10$ (decimal) and $\beta=16$ (hexadecimal);
- $-e_{min}\leq n\leq e_{max}$ is the exponent that defines the order of magnitude of the number;
- the integers $0\leq d_i\leq\beta-1$ are called the digits, while $p$ is the number of significant digits.
Note that $$ (0.d_1d_2\dots d_p)\times\beta^n = (d_1\beta^{-1}+d_2\beta^{-2}+\dots+d_p\beta^{-p})\beta^n\,. $$
It can be shown that for every $f\in F$, we have
$$ f_{min}\leq |f| \leq f_{max}\,, $$ where $$ f_{min}=\beta^{-(e_{min}+1)}\qquad\mbox{and}\qquad f_{max} = \beta^{e_{max}}(1-\beta^{-p}) $$
Numbers that are less than $f_{min}$ produce underflow, while larger numbers than $f_{max}$ will cause overflow.
Computers use base $\beta=2$ and usually suport single precision ($p=32$) and
double precision ($p=64$). In the single-precision representation we use 1 bit for the sign (0 means positive, 1 means negative), 8 bits for the exponent, and 23 bits for the mantissa (for a total of 32 bits). In the double-precision representation we use 1 bit for the sign, 11 bits for the exponent, and 52 bits for the mantissa (for a total of 64 bits). A pictorial representation of these conventions is included below (based on the IEEE754 standard -- this shows the actual order in which the various elements of a floating-point number are stored in a computer):
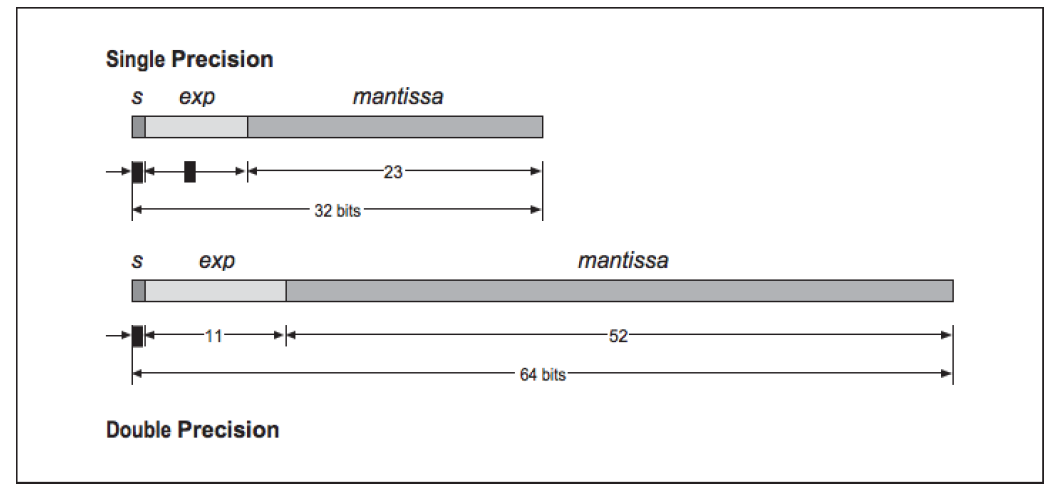
The first bit (s) is for the sign of the number.
Internally, the computer avoids using negative exponents by adding to it a bias. The relationship between the unsigned exponent ('Exp'), the bias ('Bias') and the actual exponent ('E') is described by the formula
$E = Exp - Bias$
In general, $Bias = 2^{e-1}-1$, where $e$ is the number of exponent bits:
- single precision: $Bias=127$ ($Exp:\;1\dots 254$, $E:\;-126,\dots,127$)
- double precision: $Bias=1023$ ($Exp:\;1\dots 2046$, $E:\;-1022,\dots,1023$)
To represent $81.625$ in single precision we write $81$ and $0.625$ in binary form and then add them up using the rules of binary addition. For example:
\begin{eqnarray*} 81.625 &=& (1)2^6 + (0)2^5 + (1)2^4 + (0)2^3 + (0)2^2 + (0)2^1 + (1)2^0 + (1)2^{−1} + (0)2^{−2} +(1)2^{−3}\\ &=&((1)2^{−1} + (0)2^{−2} + (1)2^{−3} + (0)2^{−4} + (0)2^{−5} + (0)2^{−6} + (1)2^{−7} + (1)2^{−8} + (0)2^{−9} + (1)2^{-10})2^7\\ &=& 0.1010001101\times 2^7 \end{eqnarray*}
For this example the exponent is going to be stored as $7+127=134$ using bias $127$. To obtain the actual exponent, compute $134-127=7$. If the exponent is $-57$, it is stored as $-57+127=70$. A stored exponent of $0$ implies an actual exponent of $-127$. Here is the internal representation for $81.625$, where $s=0$, exponent=134 in a field of 8 bits, and the mantissa follows the exponent in a field of 23 bits (the vertical bars separate these various blocks):
$0|10000110|10100011010000000000000$
Consider another example (32-bit, single precision), the decimal number $172.625$. In base 2 this becomes
$10101100.101 \times 2^0$
and if we normalise it:
$1.0101100101\times 2^7$
The internal storage of this number will be
0|10000110|01011001010000000000000
The three blocks correspond to the sign bit, the exponent, and then the mantissa (note that there are trailing zeros added to this last one because we still have space left in our storage block).
The 64-bit format is similar, except that the exponent is 11 bits long, biased by adding 1023 to the exponent, and the mantissa is 52 bits long (remember that the additional leading bit is for the sign).
Now, consider $x=1/6$, and assume that $\beta=2$ and $p=8$. The binary representation of $1/6$ is the infinite repeating pattern
$0.00101010101010101010101010101010\dots$.
Since we only have 8 binary digits to work with, when $1/6$ is stored in the computer's memory the binary sequence is either rounded or truncated. When using rounding, the approximation is $0.00101011$, but with truncation the approximation is $0.00101010$.
Real numbers vs. floating-point numbers¶
In the IEEE implementation of floating-point numbers, a non-zero number is assumed to have a hidden 1 prior to the first digit. As a result, single precision format uses 24 binary digits, and double precision 53. Also, for the IEEE implementation:
- single precision: $e_{min}=-126$ and $e_{max}=+127$
- double precision: $e_{min}=-1022$ and $e_{max}=+1023$

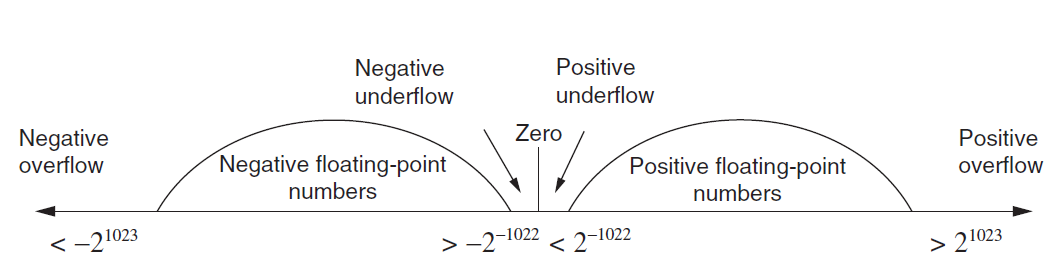
Because $F$ (the set of floating-point numbers) is finite, there is no possibility of representing the continuum of real numbers in any detail. Indeed, real numbers in absolute value larger than the maximum member of $F$ cannot be said to be represented at all (operations with such numbers will lead to overflow). The same is true of non-zero real numbers smaller in magnitude than the smallest positive number in $F$ (such numbers will cause underflow). Moreover, an element of $F$ has to represent a whole interval of real numbers.
If $x$ is a real number in the range of $F$, we denote by $$ fl(x) $$ a number in $F$ which is closest to $x$. If $x$ is equidistant between two numbers in $F$ then $fl(x)$ can take on either of the neighbouring values. It can be shown that if $x$ is in the range of $F$ then
$$ \dfrac{|fl(x)-x|}{|x|} \leq\frac{1}{2}\beta^{1-p}\,. $$
Returning to the discrete (i.e., finite) nature of our $F$: in general, an interval from $2^k$ to $2^{k+1}$ has a gap between values of $2^k(2^{-52})$ if IEEE double precision is used; you can check this by considering the cases $k=0$, $k=1$, etc, and writing down the first few elements in each of them. As $k$ increases, the gap relative to $2^k$ remains $2^{-52}$; for single precision this gap is $2^{-23}$. There is a name associated with this gap: it is called the machine precision or the machine epsilon, $eps$ for short.
Assume $\beta$ is the base of the number system, $p$ is the number of significant digits, and that rounding is used. The machine precision is
$$ eps = \frac{1}{2}b^{1-p}\,. $$
This represents the distance from $1.0$ to the next largest floating-point number.
The conversion of real numbers to floating-point numbers is called floating-point representation or rounding, and the error between the true value and the floating-point value is called
round-off error. We expect $(fl(x)-x)/x\equiv\varepsilon$ not to exceed $eps$ in magnitude. Furthermore,
\begin{equation*}
fl(x) = x(1+\varepsilon)\,,\qquad\mbox{for all}\qquad f_{min}\leq x \leq f_{max}\,,
\label{ec:66} \tag{1}
\end{equation*}
with $|\varepsilon|<eps$
For single-precision IEEE floating-point representation, $eps=2^{-23}\simeq 1.192\times 10^{-7}$, and for double-precision $eps = 2^{-52}\simeq 2.22\times 10^{-16}$. This indicates that the maximum accuracy for single- and double-precision arithmetic is 7 and 16 significant digits, respectively.
Floating-point arithmetic¶
Suppose that $x$ and $y$ are floating-point numbers (i.e., $x, y\in F$). Then the true sum $x+y$
will frequently not be in $F$. Thus, the operation of addition, for example, must be simulated on the computer by an approximation called floating-point addition.
If $x$, $y\in F$ and the number $x+y$ is in the range of $F$,
$$
x\oplus y = fl(x+y)\,,
$$
where $\oplus$ denotes floating-point addition. If $x$, $y\in\mathbb{R}$ then (obviosuly)
$$
x\oplus y = fl(fl(x)+f(y))\,.
$$
Similar notation applies for the other operations: $\ominus$ (floating-point subtraction), $\odot$ (floating-point multiplication) and $\oslash$ (floating-point division). Of course, operations with floating-point numbers can result in overflow or undereflow. Note that the machine precision can also be uniquely defined as the smallest floating-point number $eps$ such that
$$ 1\oplus eps>1 $$
Example: Assume $\beta = 10$, $p=4$ and that the true values of $x$ and $y$ are
$0.34578\times 10^1$ and $0.56891\times 10^1$, respectively. In this case,
$$
fl(x) = 0.3458\times 10^1\,,\qquad
fl(y) = 0.5689\times 10^1\,,
$$
and $x\oplus y = 0.9147\times 10^1$.
When performing floating-point operations on values with different exponents, a re-alignment must take place. For example, consider $\beta=10$, $p=5$ and
$x = 0.10002\times 10^2$, $y=0.99982\times 10^1$. Then $x\ominus y$ is computed as
follows:
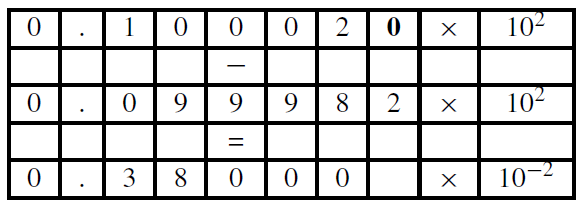
Without adding the extra $0$ in $x$ and sticking with $5$ digits throughout the calculations, we get an incorrect result:
The additional digit is called a guard digit -- such digits can be used to reduce the amount of roundoff error.
Let's consider now another example that illustrates the re-alignment mentioned above: let's say we want to add the decimal numbers $x=-3.4\times 10^2$ and $y=5.2\times 10^4$ using 3-digit precision.
\begin{alignat*}{2} x\oplus y &= (-3.4\times 10^2)+5.2\times 10^4) &&{}\\[0.2cm] &= (-3.4\times 10^2)+(520.0\times 10^2) &&\qquad\mbox{(align exponents)}\\[0.2cm] &= -(3.4+520.0)\times 10^2 &&\\[0.2cm] &= 516.6\times 10^2 &&\\[0.2cm] &= 5.166\times 10^4 &&\qquad\mbox{(fix exponent)}\\[0.2cm] &= 5.17\times 10^4 &&\qquad\mbox{(round)} \end{alignat*}
The Python code included below shows how we can do these calculations on the computer:
import numpy as np
# mimicks 3-digit precision
# (built-in Python function -- see documentation):
def fl3(xname):
tmp = np.format_float_positional(xname,
precision=3, # precision
unique=False,
fractional=False,
trim='0')
# this built-in return a string --> must be further converted...
return float(tmp)
def main():
x = -3.4*(10**2); y = 5.2*(10**4) # the original values
z = fl3(x+y) # convert the result to required precision
return z # return the answer
# call the demo function:
main()
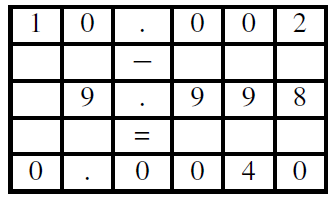
We close this section with a further discussion about guard digits. By way of example, consider a base-10 system with five digits, and assume we want to carry out the subtraction: $10.001 - 9.9993 = 0.0017$. Each one of these individual numbers can be represented using our floating-point format. Since we have only five digits of precision available, while aligning the decimal points during the computation the results end up with significant error as seen in the sketch included below:

To avoid this problem, i.e. carry out the computation and round it correctly, it is not necessary to increase the number of significant digits for stored values. What we do need is additional digits of precision while performing the computation. The fix is to add extra guard digits which are maintained during the interim steps of the computation. More specifically, if we maintained six digits of accuracy while aligning operands, and rounded before normalising and assigning the final value, we would get the correct result. The guard digits only need to be present as part of the internal floating-point execution. There is no need to add guard digits to the values stored in the computer memory (see Theorem 2 in the section 'Loss of significance').
Relative error¶
There are two ways to measure error, using absolute and relative error:
\begin{alignat*}{1}
&\mbox{absolute error}\,=\,|fl(x)-x|\,,\\[0.2cm]
&\mbox{relative error}\,=\,\frac{|fl(x) - x|}{|x|}\,,\qquad x\neq{0}\,.
\end{alignat*}
Examples: a). Take $\beta=10$ and $p=4$. The value of eps for this representation is $eps=0.0005 = 5\times 10^{-4}$. The value $x=0.34578\times 10^1$ converts to floating point as $fl (x) =0.3458\times 10^1$. According to equation $(1)$, $fl(0.34578\times 10^1) = 0.3458\times 10^1 =0.34578\times 10^1(1 + \varepsilon)$, so $\varepsilon =((0.3458\times 10^1)/(0.34578\times 10^1))-1=0.5784\times 10^{-4}< eps$, as expected. Also, $|fl (x) - x| =0.0002$, as opposed to $(|fl (x) - x|)/|x|=0.5784\times 10^{-4}$.
b). Consider $x=1.6553\times 10^5$ and assume that $fl(x) =1.6552\times 10^5$. The absolute error is $|fl(x)-x| =10$, while the relative error is $(|fl(x)-x|)/|x|=6.04\times 10^{-5}$. With large numbers, relative error is generally more meaningful, as we see here.
c). The relative error gives an indication of how good a measurement is relative to the size of the thing being measured. Let’s say that two people measure independently the distance to different objects One person obtains a value of $d_1 =28.635$ m, and the true distance is $d_1=28.634$ m. The other person determines the distance is
$d_2 =67.986$ m, and the true distance is $d_2 =67.987$ m. In each case, the absolute error is $0.001$. The relative errors are:
\begin{alignat*}{1}
\mbox{first distance:}\qquad(|28.634 − 28.635|)/|28.634|=3.49×10^{-5}\,,\\[0.2cm]
\mbox{second distance:}\qquad(|67.987 − 67.986|)/|67.987|=1.47×10^{-5}\,.
\end{alignat*}
The relative error of measurement $d_2$ is about $237\%$ better than that of measurement $d_1$, even though the amount of absolute error is the same in each case.
Relative error provides a much better measure of change for almost any purpose.
A common situation: Assume we want to estimate a quantity that is defined iteratively, but we do not know the actual (i.e., true) value of that quantity. For the sake of the argument, assume that we are trying to estimate the infinite sum
$$
\sum_{k=1}^\infty\frac{1}{k^2+\sqrt{k}}\,.
$$
Obviously, in this case we need to calculate the partial sums $s_n = \sum_{k=1}^n 1/(k^2+\sqrt{k})$; but how many terms should we allow in the sum? Typically, we would want our result to provide an approximation of the true value to within a specified tolerance, $TOL$ (say). There are two approaches commonly used:
a). compute partial sums until $|s_{n+1}-s_n|<TOL$; or,
b). compute partial sums until $\dfrac{|s_{n+1}-s_n|}{|s_n|}<TOL$.
Both approaches are valid, but the latter is preferable because it tells us how the new partial sum is changing relative to the previous sum.
OBS. The computer implementation of floating-point addition typically satisfies the property that the relative error is less than the machine epsilon,
$$
\frac{|(x\oplus y)-(x+y)|}{|x+y|}\leq eps\,.
$$
Rounding error bounds¶
The floating-point representation leads to small errors that tend to propagate in a numerical algorithm. Understanding such errors leads to means of controlling them. A few important results are stated below (without proof).
1). When adding $n$ floating-point numbers, the result is the exact sum of the $n$ numbers, each perturbed by a small error. It can be shown that the errors are bounded by $(n-1)eps$, where $eps$ is the machine epsilon.
2). The relative error in computing the product of $n$ floating-point numbers is at most $1.06(n-1)eps$, assuming that $(n-1)eps<0.1$.
Loss of significance¶
Suppose we want to calculate $\sqrt{10}-\pi$ using a computer with precision $p=6$. Then
$\sqrt{10}\simeq 3.16228$ with an absolute error of about $2\times 10^{-6}$ and $\pi\simeq 3.14159$ with an absolute error of about $3\times 10^{-6}$. The absolute error in the result
$\sqrt{10}-\pi\simeq 0.02069$ is about $5\times 10^{-6}$. However, calculating the relative error, we get approximately
$$
\frac{5\times 10^{-6}}{0.02068}\simeq 2\times 10^{-4}\,,
$$
which is about $100$ times as big as the relative error in $\sqrt{10}$ or $\pi$. This problem is known as loss of significance. It can occur when two similar numbers of equal sign are subtracted (or two similar numbers of opposite sign are added).
Another example: Let's assume $\beta=10$ (base) and $p=6$ (precision), together with the numbers $x=1.00000$ and $y=9.99999\times 10^{-1}$.The true difference of these numbers is $x-y = 0.000001$. However, when calculating the difference, the computer first adjusts the magnitude so that the two numbers have the same magnitude; this way the second number becomes $y=0.99999$ -- note that we have lost one digit in $y$. The computed result is $1.00000-0.99999 =0.00001$, so the absolute error is $|0.000001-0.00001|=0.000009$. Hence, the relative error is $0.000009/0.000001 = 9$, i.e. $\beta-1$.
We state without proof two important theorems related to loss of significance:
Theorem 1: Using floating-point format with parameters $\beta$ (base) and $p$ (precision), and computing differences using $p$ digits, the relative error of the result can be as large as $\beta-1$.
The unsatisfactory result of the above example can be avoided by the introduction of a guard digit. That is, after the smaller number is shifted to have the same exponent as the larger number, it is truncated to $(p+1)$ digits. Then the subtraction is performed and the result is rounded to $p$ digits. An estimate of the relative error in this case is provided by the following result:
Theorem 2: If $x$ and $y$ are positive floating-point numbers in a format with parameters $\beta$ (base) and $p$ (precision), and if the subtraction is done with $(p+1)$ digits (i.e., 1 guard digit), then the relative error in the result is less than $(\frac{\beta}{2}+1)\beta^{-p}$.
Robustness¶
An algorithm is described as robust if for any valid data input which is reasonably representable, it completes successfully.
This is illustrated by a simple example. Subtraction of numbers that are very close can lead some fairly baffling results. This is sometimes referred to as cancellation error. We are going to focus on solving a quadratic equation to illustrate this behaviour. The solution of the quadratic equation
$$
ax^2 + bx + c = 0\,,\qquad (a\neq{0})\,,
$$
is given by the well-known formulae:
$$
x_1 = \frac{-b+\sqrt{b^2-4ac}}{2a}\quad\mbox{and}\quad
x_2 = \frac{-b-\sqrt{b^2-4ac}}{2a}\,.
$$
A problem arises if $b^2\gg |4ac|$ because in this case $\sqrt{b^2-4ac}\simeq b$, and in one of the above formulae we would be subtracting two nearly equal numbers. This is a serious problem, since we know that a computer keeps only a fixed number of significant digits. For a concrete example, consider
$$
a = 1\,,\qquad b=68.50\,,\qquad c = 0.1\,,
$$
and let's use rounded base-10 arithmetic with 4 significant digits. Note that
$$
b^2-4ac = 4692 - 0.4000 = 4692\,,
$$
and
\begin{alignat*}{1}
x_1 &= \frac{-68.50+\sqrt{4692}}{2} = \frac{-68.50 + 68.50}{2} = 0\,,\\[0.2cm]
x_2 &= \frac{-68.50 - \sqrt{4692}}{2} = \frac{-68.50 - 68.50}{2} = -68.50\,.
\end{alignat*}
We can check these calculations with the Python code included below:
import numpy as np
# mimicks 4-digit precision
# (i.e., p=4 in the general representation):
def fl4(xname):
tmp = np.format_float_positional(xname,
precision=4, # precision
unique=False,
fractional=False,
trim='0')
return float(tmp)
# function to get the coefficients of the quadratic:
def get_inputs():
a_coeff = 1.0
b_coeff = 68.50
c_coeff = 0.1
return a_coeff, b_coeff, c_coeff
# solver for the quadratic using 4-digit precision:
def solve():
a, b, c = get_inputs()
D = fl4(b*b)-fl4(4.0*a*c)
x1 = fl4(fl4((fl4(-b)+fl4(np.sqrt(D)))/fl4(2.0*a)))
x2 = fl4(fl4((fl4(-b)-fl4(np.sqrt(D)))/fl4(2.0*a)))
return x1, x2
# demo for the above code:
def main():
tmp1, tmp2 = solve()
print('First root is: ', tmp1)
print('Second root is: ', tmp2)
# call the main function:
main()
The correct roots are
$$
x_1 = -0.001460\qquad\mbox{and}\qquad x_2 = -68.50\,.
$$
The relative error in computing $x_1$ is
$$
\frac{|-0.001460-0.0000|}{|-0.001460|} = 1.0000\,,
$$
which is awful; however, $x_2$ is correct. The cancellation error can be avoided by writing the quadratic formula in a different way.
To this end, we start with the observation that $x_1x_2=c/a$, as the calculation included below confirms:
$$
\left(\frac{-b+\sqrt{b^2-4ac}}{2a}\right)\left(\frac{-b-\sqrt{b^2-4ac}}{2a}\right)
= \frac{b^2-(b^2-4ac)}{4a^2} = \frac{4ac}{4a^2}=\frac{c}{a}\,.
$$
Pick one of the two solutions for which there is no loss of accuracy in the numerator, and call it $x_1$, i.e.
$$
x_1 = -\left(\frac{b+{\text{sgn}}(b)\sqrt{b^2-4ac}}{2a}\right)\,,
$$
where ${\text{sgn}}(b)=+1$ if $b>0$, and ${\text{sgn}}(b) = -1$ if $b<0$. We can then compute the other solution, $x_2$, from $ x_2 = \dfrac{c}{ax_1}$ so that cancellation error is avoided. For our example
\begin{alignat*}{1}
&x_1 = -\left(\frac{68.50 + 68.50}{2}\right)=-68.5\,,\\[0.2cm]
&x_2 = \frac{0.1}{(1)(-68.5)} = -0.001460\,.
\end{alignat*}
Another way to avert the issue highlighted above is described next. Assume without loss of generality that $b>0$ and that the small root is given by
$$
x = \frac{-b+\sqrt{b^2-4ac}}{2a}\,.
$$
We can write
\begin{eqnarray*}
x &=& \frac{-b+\sqrt{b^2-4ac}}{2a}\times\left(\frac{-b-\sqrt{b^2-4ac}}{-b-\sqrt{b^2-4ac}}\right)\\[0.2cm]
&=&\frac{b^2-(b^2-4ac)}{2a(-b-\sqrt{b^2-4ac})}\\[0.2cm]
&=&\frac{-2c}{b+\sqrt{b^2-4ac}}\,,
\end{eqnarray*}
where use was made of the formula $(X-Y)(X+Y) = X^2-Y^2$ (valid for any $X$, $Y\in\mathbb{R}$). Note that now quantities of similar size are added instead of subtracted.
In general, adequate analysis has to be conducted to find cases where numerical difficulties will be encountered, and a robust algorithm must use an appropriate method in each case.
REFERENCES:
1). D. Goldberg: What every computer scientist should know about floating-point arithmetic, ACM Computing Surveys, vol. 23, 1991.
2). N.J. Higham: Accuracy and Stability of Numerical Algorithms, SIAM, Philadelphia, 2002.
3). G.E. Forsythe, M. Malcolm, C.B. Moler: Computer Methods for Mathematical Computations, Prentice Hall, New Jersey, 1977.